

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 악성코드 분석
- webhacking
- Dreamhack
- SK쉴더스루키즈
- 루키즈31기
- linux
- 웹개발
- 깃
- 프랑스어 #프랑스어배우기 #프랑스어독학 #델프인강 #시원스쿨프랑스어 #delf독학 #델프 #프랑스어기초 #프랑스어공부
- 루키즈 31기
- 다이나믹 프로그래밍
- 코리안챔버오케스트라
- 위상 정렬
- 예술의 전당
- 애플리케이션 계층
- 백엔드
- React
- 알고리즘
- SK쉴더스
- 서울청년문화패스
- 우테코
- 진입차수
- c
- 자바
- sk쉴더스 루키즈
- 레나튜토리얼
- sk 쉴더스 루키즈
- 프리코스
- 우아한테크코스
- 트랜스포트 계층
- Today
- Total
yon11b
[SK 쉴더스 루키즈] 딥러닝 모델 CNN, RNN 본문
CNN
이미지 처리에 특화된 딥러닝 모델
핵심 구성 요소
1. Convolution Layer
합성곱 층
작은 필터를 이미지 위에 슬라이딩하면서 특징을 추출한다.
앞쪽 층: 단순한 특징(선, 엣지)
뒷쪽 층: 복잡한 특징(눈, 코, 얼굴)
윤곽을 알아내는 방법

x filter: 오, 왼 차이가 크다. (-2, +2)
y filter: 위, 아래 차이가 크다. (-2, +2)
윤곽선 차이 대비를 크게 줘서 확실히 구별을 할 수 있도록 함.
2. Pooling
압축/요약
3. Fully Connected
분류 결정
CNN 확장 모델
CNN 확장1: 더 깊게(ResNet)
문제
층을 깊게 쌓으면 학습이 잘 안 됨
기울기 소실 발생
해결
"기본값(입력)을 보존한 채로, 필요한 변화만 학습한다"
- 기존 CNN: 👉 “완전히 새로 학습해야 함”
- ResNet: 👉 “기존 값 유지 + 필요한 부분만 수정”
CNN 확장2: 효율, 성능(인셉션, EfficientNet)
문제
- 어떤 필터 크기가 좋은지 모름 (1x1? 3x3? 5x5?)
- 아무렇게나 깊이, 너비, 해상도 올리면 비효율
해결1: 다 써보자!!
인셉션
- 한 층에서 여러 크기 필터를 동시에.
- 한 레이어에서 여러 크기의 필터를 병렬로 적용
해결2: 비율 맞춰서 같이 키우자!
EfficientNet
- 균형있게 키워서 효율적으로 성능 높임
기존 문제
보통 하나만 키움:
깊이(depth) 또는 너비(width) 또는 이미지 크기(resolution)
=> 근데 균형이 안 맞음.
=> 깊이, 너비, 해상도를 균형 있게 같이 키우자
CNN 확장3: 특정 과제용(U-Net, YOLO 등)
왜 특정 과제용 필요?
일반 CNN 분류: 어떤 물체이지 식별하는데만 강함
실제 문제: 픽셀 단위로 경계까지 알아야 함
U-Net
- 픽셀 단위로 정확히 구분하는 것이 목적
- 활용
- 사진 편집에서 특정 물체만 자르기 해서 없애기.(경계구분)
- 의료 분야: 암 위치 식별
YOLO
- 물체 위치를 빠르게 찾는 것이 목적
- 활용
- 자율주행
- CCTV
- 실시간 객체 탐지
RNN
앞 정보를 다음 시점으로 넘겨서 기억을 흉내낸다.
u: 입력 / x: 상태 / y: 출력
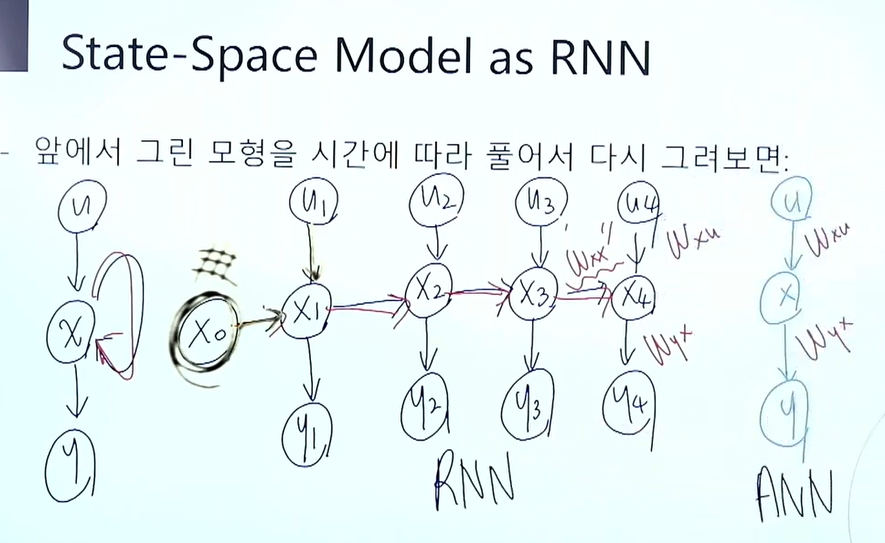
RNN의 한계
1. 데이터가 긴 경우
- hidden state 를 계속 압축해서 전달하므로 -> 초반 정보가 뒤로 전달되기 어려움
2. 기울기 소실, 폭주 문제
- 가중치가 1보다 작으면
- 점점 0에 가까워짐 -> 그러면 앞쪽 층/RNN 초반 시점까지 학습 신호가 거의 전달되지 않는다.
- 가중치가 크면
- 기울기 폭주
- loss가 튐
- weight가 발산
- 학습 불안정
- 기울기 폭주
3. 순차 계산이라 병렬화가 어려움(속도 한계)
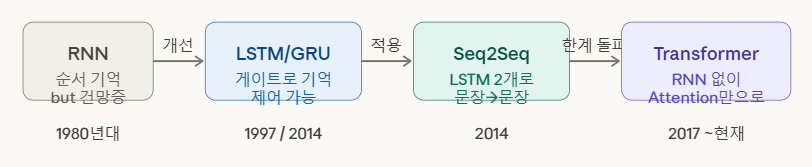
해결
LSTM/GRU, Attention, Transformer
RNN 확장 모델
RNN 확장1: LSTM/GRU(기억을 게이트로 제어)
문제상황: 문장이 길어지면 앞의 정보를 잊는 문제
핵심 아이디어
- 기억을 통째로 다 넘기는 게 아니라 게이트로 제어한다.
- 필요한 정보는 유지하고 불필요한 정보는 삭제하는 방식
LSTM
셀 상태: 중요한 기억을 오래 저장하는 전용 통로
구조
- 입력 게이트
- 삭제 게이트
- 출력 게이트
정확도 좋음
But 느림, 복잡
GRU
LSTM 단순화한 구조 -> cell state 가 없음
구조
- 업데이트 게이트
- 과거 기억을 얼마나 가져갈지 결정
- 값이 크다 -> 이전 기억 오래 유지
- 값이 작다 -> 새 정보로 교체
- 리셋 게이트
- 과거 기억을 참고해서 새 기억을 만들지 결정
- 값이 크다 -> 과거 기억 참고
- 값이 작다 -> 과거 기억 무시
RNN 확장2: Seq2Seq(번역/요약의 기본 뼈대)
개념
- 문장→문장 변환
- 입력이 문장이고 출력도 문장인 문제를 푸는 구조
- ex) 번역(영→한), 문장 요약, 초기 챗봇
인코더, 디코더
- 인코더: 입력 문장을 읽고 핵심 의미를 요약해서 저장
- 디코더: 저장된 의미를 바탕으로 출력 문장을 한 단어씩 생성
- 흐름: 입력 시퀀스 → 인코더 요약 → 디코더가 출력 시퀀스 생성

인코더에 한글 → 한글 정보들을 함축해서 h3에 전달.
디코더는 h3를 보고 번역 시작.
처음 번역된 artificial은 다음 추론에 입력으로 또 들어감. 그래서 intelligence를 추론함.
근데 초기에는 학습이 잘 안된 상태이기 때문에 잘못된 단어를 내뱉을 수 도 있음(humanity)
그럼 다시 역전파 시킨다.
Teacher-forcing
다음 인풋에는 잘못 추론한 단어가 아니라 정답 단어를 인풋으로 넣는다.
(훈련하는 상황이라 정답을 알고 있음)
한계
메모 한 장에 다 넣기 어려움
해결 → 어텐션이 붙음
디코더가 출력 단어를 만들 때마다 입력 문장 중 지금 중요한 부분을 다시 집어서 참고하게 함
⇒ Seq2Seq + Attention 구조 가 표준이 됨
Attention: 필요한 부분을 직접 참조
- 출력 시점에 입력 전체를 훑음.
- 중요한 토큰에 가중치 줌
- 긴 문장에서도 중요한 정보가 멀리 있어도 바로 연결됨
Transformer
Attention을 중심으로 문장을 처리하는 모델
RNN처럼 한 단어식 순서대로 처리하는 게 아니라 전체를 한번에 보면서 중요한 관계를 찾음

인코더랑 디코더가 한 줄로 이어져 있는 것이 아니라 attention으로 전체 정보를 참조하는 구조이다.
장점
- 병렬 학습이 쉬움: 한 번에 계산 → GPU 에 유리
- 긴 문맥에 강함: 멀리 떨어진 관계도 attention으로 잘 잡음
키워드
- self-attention: 문장 안에서 어떤 단어가 어떤 단어를 참고해야 하는지 가중치 계산
- multi-head: attention을 여러 관점으로 동시에 봐서 표현을 풍부하게 함
- positional encoding: 순서 정보가 없으니 몇 번째 단어인지 위치 정보를 추가
사용 사례
- NLP: 번역, 요약, 챗봇, 문서 분석
- 비전 트랜스포머(ViT)로 이미지 처리
- 멀티모달: 텍스트+이미지+음성 같이 다루는 모델에도 사용
'보안 > SK 쉴더스 루키즈' 카테고리의 다른 글
| [SK 쉴더스 루키즈] notepad로 알아보는 PE 파일 구조 (feat: PEview) (0) | 2026.05.27 |
|---|---|
| [SK 쉴더스 루키즈] AWS 모니터링 (0) | 2026.05.13 |
| [SK 쉴더스 루키즈] 리눅스/윈도우 서버에서 자동 진단 수행하기 (0) | 2026.05.09 |
| [SK 쉴더스 루키즈] 중앙집중형 로그 관리 환경 구축(Fluent-Bit, OpenSearch Dashboard) (0) | 2026.05.09 |
| [SK 쉴더스 루키즈] notepad++ 무결성 검증하기 (0) | 2026.05.09 |


