

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 레나튜토리얼
- sk 쉴더스 루키즈 31기
- 백엔드
- 진입차수
- c
- 우아한테크코스
- 루키즈
- SK쉴더스루키즈
- 코리안챔버오케스트라
- React
- 루키즈 31기
- 웹개발
- 위상 정렬
- Dreamhack
- 동적분석
- 예술의 전당
- linux
- 알고리즘
- 루키즈31기
- 악성코드 분석
- 프랑스어 #프랑스어배우기 #프랑스어독학 #델프인강 #시원스쿨프랑스어 #delf독학 #델프 #프랑스어기초 #프랑스어공부
- 자바
- 깃
- sk 쉴더스 루키즈
- 우테코
- 서울청년문화패스
- 프리코스
- Practical Malware Analysis Labs
- sk쉴더스 루키즈
- webhacking
- Today
- Total
yon11b
[SK 쉴더스 루키즈] 보안관제 - Splunk 사용법 & vim에서 데이터 전처리 & Excel 피벗 테이블 본문
[SK 쉴더스 루키즈] 보안관제 - Splunk 사용법 & vim에서 데이터 전처리 & Excel 피벗 테이블
yon11b 2026. 6. 11. 03:46Splunk
http://127.0.0.1:8000/ko-KR/app/launcher/home
기본 구조
- monitor: splunk가 특정 파일을 지속적으로 감시하는 기능
- forwarder: 로그 수집기. 수집한 로그를 indexer로 전송
- indexer: 로그 저장소. forwarder가 보낸 로그를 받아서 인덱싱 후 저장
- 실제 데이터가 들어있는 공간
- search head: 검색 서버. 사용자가 웹에서 검색하는 대상
- master(cluster manager): indexer 여러 대를 관리하는 서버
로그 발생 서버
↓
Forwarder
↓
Indexer
↓
Search Head
검색
기본용어
- 필드(Field) = 항목 이름
- 값(Value) = 그 항목에 들어있는 데이터
연산자: 다 대문자영어로 씀
AND, OR, NOT, IN 등
기본 검색에서는 따옴표 안 써도 됨
user=admin
SPL 명령어에서는 따옴표 필수임
SPL 명령어: where, eval 등
| where user="admin"
필드를 지정하지 않으면 _raw 검색
admin
필드 지정없이 냅다 이 검색어만 쓰면 자동으로
_raw="admin"
이렇게 검색한다.
연산자를 안 쓰면 자동으로 AND 지정
admin login
이렇게 검색하면 splunk는 아래와 같이 바꿔서 검색한다.
admin AND login
즉, 둘 다의 값이 포함된 로그만 찾는다. (필드아님)
필드와 연산자는 대소문자를 구분, 검색어는 구분x
연산자는 무조건 대문자!
와일드카드 사용
검색에서만 가능하다.

count by(in splunk) vs group by(in sql)
이 둘은 똑같은 의미이다.
| stats count by method
SELECT method, COUNT(*)
FROM apache_log
GROUP BY method;
결과
| method | count |
| GET | 100 |
| POST | 20 |
| PUT | 5 |
집계 SPL 명령어 : stats & charts
1. stats: count가 하나의 필드로 생성된다.
통계 테이블 생성
index=apachelog
| stats count by method
| method | count |
| GET | 100 |
| POST | 20 |
| PUT | 5 |
후처리할 일이 많으면 stats를 더 많이 쓴다.
2. chart: count가 필드로 생성되지 않는다.
그래프용 집계
index=apachelog
| chart count by method| GET | POST | PUT |
| 100 | 20 | 5 |
바로 막대그래프, 파이차트 그릴 때 사용한다.
eval 명령어: 새로운 필드 생성 / 필드끼리 계산
index="apachelog"
| eval test="1234"
모든 이벤트에 test라는 새 필드를 만들고 값을 1234로 넣어라
변형: 다른 필드 값(method, status) 가져오기 + 중간에 문자열 넣기
index="apachelog"
| eval test = method + " " + status
내림차순 정렬 -
index="apachelog"
| stats count by method
| sort - count
method에 대해서 count 필드를 기준으로 내림차순 정렬
SQL 표현
select method, COUNT(*) as count
from apachelog
group by method
order by count desc ;
bin 간격
기본: 자동으로 간격을 잡아줌
index="apachelog"
| bin _time
| stats count by _time
커스텀 설정 - 1시간 단위
index="apachelog"
| bin _time span=1h
| stats count by _time
시각화 차이 in stats, chart
stats: method 값이 필드로 남아있다.
index="apachelog"
| bin _time
| stats count by _time, method
| _time | method | count |
| 10:00 | GET | 100 |
| 10:00 | POST | 20 |
| 10:05 | GET | 120 |
표로 그렸을 때
- count가 필드로 들어감.
- count, time, method가 필드임.
차트로 그렸을 때
- x축: time
- y축: count
- 범례: method가 하나의 그룹화 필드로 들어감
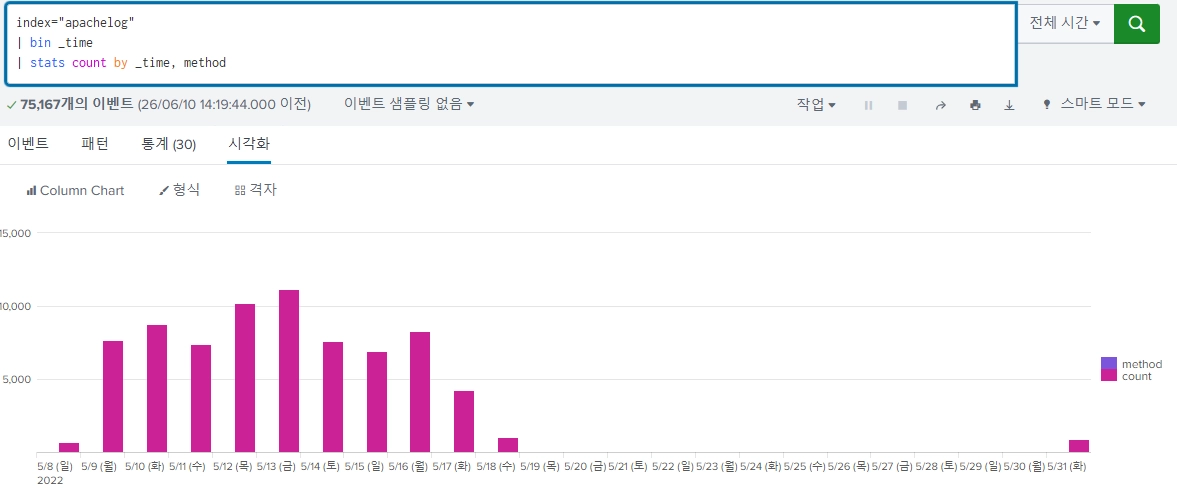
charts: method 값을 컬럼(Column)으로 펼쳐버린다(Pivot).
index="apachelog"
| bin _time
| chart count by _time, method
표로 그렸을 때
- time, method가 필드임. 값이 바로 count
| _time | GET | POST |
| 10:00 | 100 | 20 |
| 10:05 | 120 | 30 |
차트로 그렸을 때
- x축: time
- y축: count
- 범례: GET, HEAD, OPTIONS, POST (method의 세부적인 값들)

timechart: 시간(_time)을 기준으로 자동 집계 + 자동 그래프용 변환
index="apachelog"
| timechart count by uri_path limit=20
- uri path별 요청수를 시간 축으로 집계
- 가장 많이 나온(count) uri 20개만 시계열 그래프로 보여라
누적 그래프로 표현
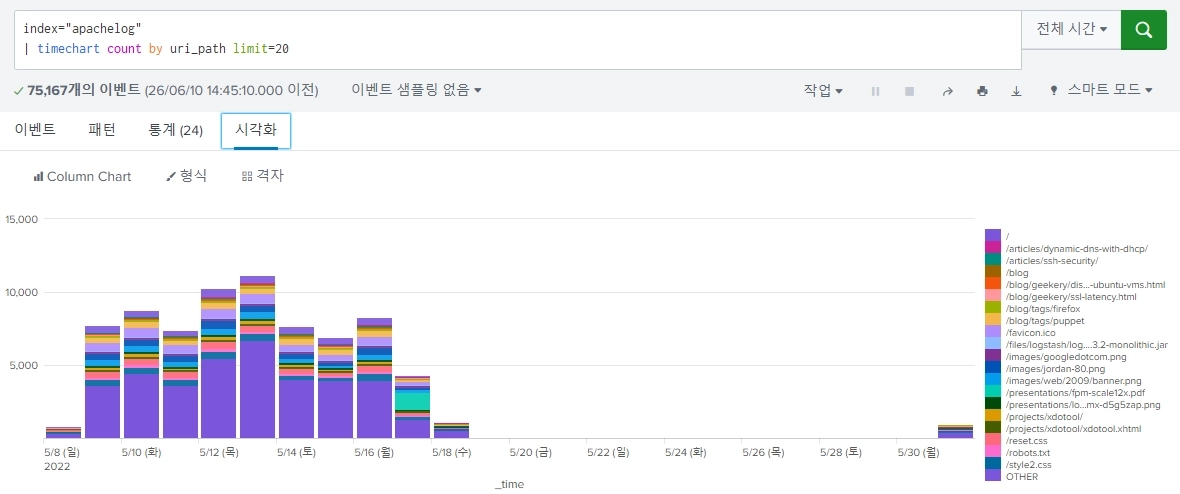
GET 메소드 제외한 나머지 메소드들만 출력
index="apachelog" NOT method="GET"
| timechart count by method
Excel에서 데이터 정제해서 보기
75000여개의 데이터가 있다. 이 데이터를 잘 가공해서 엑셀에 예쁘게 나타내보자.

1. 공백 기준으로 데이터 분리
그냥 바로 복붙하면 A열에 데이터가 다 몰려있다.

공백을 기준으로 나눠주면 깔끔하게 나눠진다.

결과 화면
여기서 필요없는 열 지우고, 제목 행 생성해준 모습이다.

2. Timestamp 가공하기
timestamp를 보니까 필터링을 걸기가 어렵게 생겼다.

날짜 형식이 이상하다. 년월일 시분초 형식으로 바꿔주자.

우선 각 요소들을 먼저 각각 검사해준다.
이렇게 구분한 다음 ()로 묶어서 그룹 저장해준다.
그리고 그룹의 순서를 바꾸고, 중간에 문자열로 잘 이어주면 될 것이다.


인식했으면, 수정은 vim에서 해주자
1. 일단 May는 05월로 바꿔준다.

2. 각각의 요소들을 검사해준다.
년월일은 /로 구분이 되어있고, 시분초는 :로 구분이 되어있다.
| 패턴 | 의미 |
| \v | very magic 모드 |
| ^ | 문자열 시작 |
| .. | 아무 문자 2개 |
| \/ | / 문자 |
| .. | 아무 문자 2개 |
| \/ | / 문자 |
| .... | 아무 문자 4개 |
| : | : 문자 |
| .* | 뒤에 아무 문자 0개 이상 |
\v를 쓰는 이유?
Vim은 기본적으로 특수문자를 많이 이스케이프해야 한다.
+, (), {} 등을 전부 \ 붙여야 하는 경우가 많다.
그런데 \v를 붙이면 very magic mode 가 되어서 일반 정규표현식(PCRE 비슷한 문법)처럼 사용할 수 있다.
보통 정규표현식에서 시작조건(^), 종료조건($)은 지정해주는 것이 좋다.
예를 들어 여기서는 ^를 쓴 것 처럼.
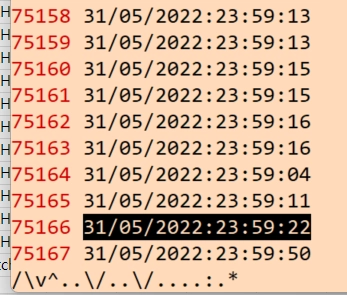
/\v^(..)\/(..)\/(....):(.*)
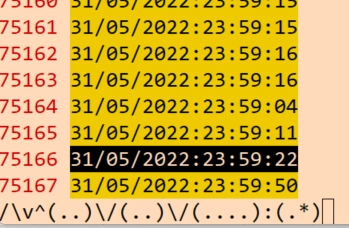
이렇게 하면 group 1,2,3,4에 각각의 정보가 저장이 된 것이다.
\1 = 31
\2 = 05
\3 = 2022
\4 = 23:59:22
//로 직전에 검색한 문자열(그룹저장명령어에서 기억됨)을 \3-\2-\1 \4의 형태로 치환해주는 명령어이다.
:%s//\3-\2-\1 \4/


그룹 3,2,1,4 순서로 재정렬하고,
년도랑 월은 -로 구분, 월이랑 일도 -로 구분, 일이랑 시간은 공백으로 구분해준다.
이제는 엑셀에서 시간 포맷으로 잘 인식을 해주게 된다.

3. URI params 구분해주기
엑셀에서 URI 부분만 가지고 왔다.

지금은 URI 하나의 컬럼만을 가지고 있지만, 이제는 URI와 method, param를 구분해서 열을 만들어보자.
1. HTTP version 정보 삭제
1. HTTP/1.1과 같은 필요없는 정보들을 삭제해주기 위해 우선 검사를 먼저 해준다.
정규식 방법 1
/ http\/\d\. \d공백
http
\/: 슬래시
\d: 숫자
\.: 점
\d: 숫자
정규식 방법 2
/ http\/.*
2. 검사로 기억된 문자열을 삭제하기
:%s///
뒤에 HTTP/1.1이 다 사라졌다.
2. method 분리
방법1
ㅋ 문자를 method와 uri 사이에 집어넣는다. 나중에 ㅋ을 기준으로 분리해주면 분리하기 쉽기 때문.
GET 다음에 공백이 있으므로 제일 처음 발견되는 공백 자리에 ㅋ을 넣어주면 된다.
:%s/ /ㅋ/
그리고 전체 문자열을 엑셀에 붙여넣고 아까 했던 것처럼 텍스트 나누기를 해주는데 이번에는 공백이 아니라 ㅋ을 기준으로 나누면 잘 나눠질 것이다.
방법2
첫번째 공백 포함 그 뒤 모든 문자열을 검사한 후, 이 문자열들을 삭제하면 method만 남을 것이다.
공백있고 그 뒤로 0개 이상의 문자열이 쭉 있는 것
/ .*

:%s///

전체를 복사해서 엑셀에 method 컬럼을 하나 만들고 붙여넣는다.

3. URI 분리
GET /blog/geekery/xvfb-firefox.htm보통 이렇게 생겼다.
GET 을 제외하는 방식으로 간다고 생각하면, GET 을 검사해야 하므로,
맨 첫번째 공백이 나오기 전까지를 검사한다.
즉, /.* 이렇게 하면 될 것 같다. (맨 뒤에 공백 한 칸 있다.)
/ → 슬래시 1개
.* → 아무 문자 0개 이상 (가능한 많이)
→ 공백 1개
그런데 만약 uri 뒤에서 또 공백이 나온다면?
GET /blog/tags/net neutrality이런 경우에는 정규식이 뒤까지 검사를 한다.
즉, 이런식으로 되는 것이다.

그럼 어떻게 해야 할까?
/\v^.{-0,}\s
- . : 아무 문자 1개
- {-0,} : 최소 0개 이상 반복 (일치하는게 나오면 중지)
- \s : 공백 문자
=> 공백이 나올 때까지 가능한 짧게 문자들을 매칭

그럼 우리가 원하는대로 검사가 된다.
그 검사한 거를 다 지워주자.
:%s///
이제 진짜 URI만 남았다.
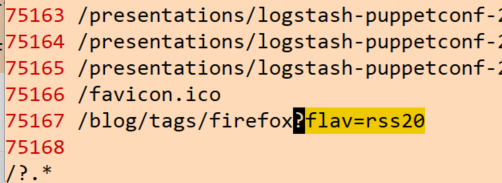
4. params 분리
?를 기준으로 분리를 하면 될 것 같다. 그런데 ?뒤는 남기고, 아닌 것은 다 삭제를 해주게 되면, ? 자체가 없는 행들도 다 삭제가 되버린다. 우리는 vim에서 가공한 데이터 전체를 복붙해서 엑셀로 가져와야 하기 때문에 행이 사라지면 안 된다.

1. 일단 ?를 기준으로 검사 먼저
/?.*
:v// 는 마지막 검색 패턴에 매칭되지 않는 줄을 대상으로 명령을 수행한다.
:v//d
검색된 줄 빼고 나머지를 다 삭제
:v//s/old/new/
검색된 줄을 제외한 나머지 줄에서 치환
:v//s/.*//기억된 부분의 줄 이외에서만 아무것도 아닌 걸로 ("")치환 작업을 하겠다.
그럼 이렇게 잘 지워진다.

이제 여기서는 ?만 검사해주면 된다.
/.*?
:%s///
이걸 복붙해서 엑셀에 넣어주자.
결과 화면

피벗 테이블
엑셀에서 데이터를 자동으로 요약, 집계해주는 기능
피벗 테이블의 4개 영역은 SQL로 생각하면 이해가 쉽다.
| 영역 | 의미 | SQL 비유 |
| 행(Row) | 세로로 그룹화 | GROUP BY |
| 열(Column) | 가로로 그룹화 | GROUP BY |
| 값(Value) | 집계할 데이터 | COUNT, SUM, AVG |
| 필터(Filter) | 전체 데이터 조건 | WHERE |

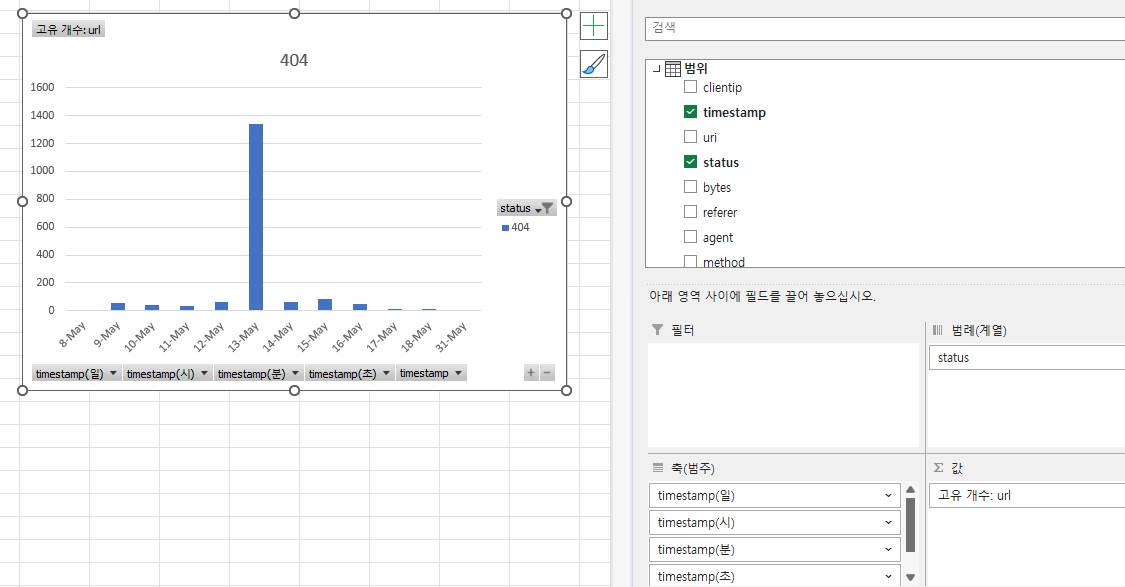
행(x축)에 시간을 두고 그룹화하고, 값(y축)에 timestamp에 대한 개수를 지정한다. 이렇게 해주면 왼쪽의 테이블이 나타나게 된다.
여기서 저 테이블을 차트로 나타내고 싶다면 아래 막대그래프를 선택해주자.

그리고 범례로 status도 넣어주자. 그럼 status별 count값이 나온다.

이번에는 url 개수를 시간별로 차트에 나타내보자.

기본은 개수이다.
쟤를 고유개수로 바꿔주자.
사용자들이 서로 다른 url에 접속하는 과정에서 404에러가 1100여개가 났다는 것을 알 수 있다.
'보안 > SK 쉴더스 루키즈' 카테고리의 다른 글
| [SK 쉴더스 루키즈] Splunk 차트 그리기 & 대시보드 & 룩업 (1) | 2026.06.12 |
|---|---|
| [SK 쉴더스 루키즈] Splunk Universal Forwarder를 이용한 로그 수집 및 전송 (0) | 2026.06.11 |
| [SK 쉴더스 루키즈] AutoIt 스크립트 분석(Citadel 변종 증명) (0) | 2026.06.06 |
| [SK 쉴더스 루키즈] Malware Traffic Analysis - INFECTION TRAFFIC FROM ITALIAN DHL-THEMED MALSPAM 문제 풀이 (0) | 2026.06.06 |
| [Malware Traffic Analysis] Email Roulette 문제 풀이 (0) | 2026.06.06 |



