

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- webhacking
- c
- 자바
- 서울청년문화패스
- 악성코드 분석
- 프리코스
- SK쉴더스루키즈
- 위상 정렬
- sk 쉴더스 루키즈
- 진입차수
- sk 쉴더스 루키즈 31기
- 알고리즘
- 코리안챔버오케스트라
- Dreamhack
- 예술의 전당
- 프랑스어 #프랑스어배우기 #프랑스어독학 #델프인강 #시원스쿨프랑스어 #delf독학 #델프 #프랑스어기초 #프랑스어공부
- 깃
- 우테코
- 동적분석
- 우아한테크코스
- sk쉴더스 루키즈
- 웹개발
- Practical Malware Analysis Labs
- 레나튜토리얼
- 백엔드
- 루키즈
- 루키즈31기
- linux
- React
- 루키즈 31기
- Today
- Total
yon11b
[SK 쉴더스 루키즈] Splunk 차트 그리기 & 대시보드 & 룩업 본문
차트 그리기
시간대별로 각 URL 별 count 개수
index="apachelog"
| timechart count by url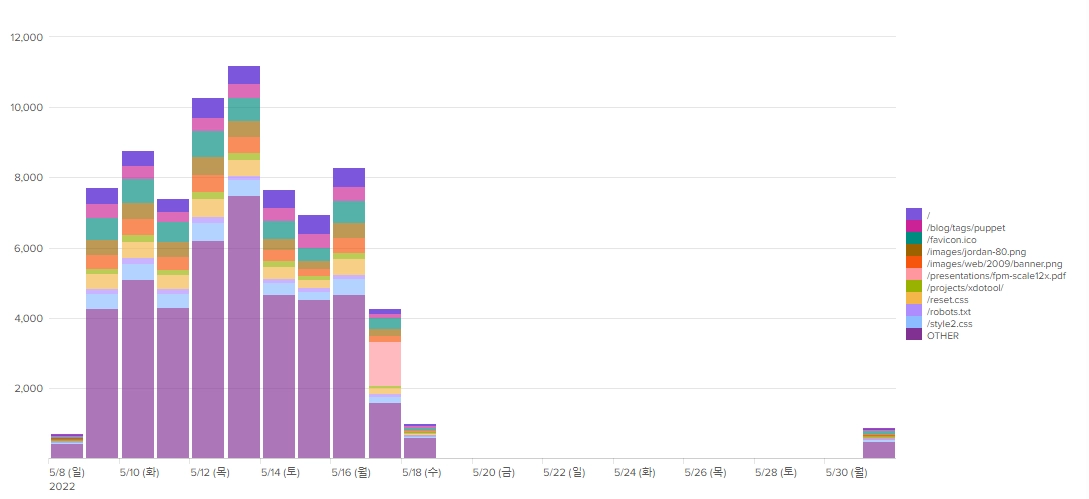
같은 url에 대해서만 몇 개의 중복된 요청이 있었는지를 표시한다.
실제 데이터셋에서 url은 아주 많기 때문에 top 10개만 뽑아서 보여준다. (limit 10)
시간대별로 상태코드마다 몇 개의 서로 다른 URL이 요청되었는가?
index="apachelog"
| timechart dc(url) by statusdc: distinct count

대시보드
두개 그려놓고 비교해서 보자.
1. distinct count URL 차트
2. status로 구분되는 distinct count URL차트

1. distinct count URL 차트
index="apachelog"
| timechart dc(url)
2. status로 구분되는 distinct count URL차트
index="apachelog"
| timechart dc(url) by status
검색조건 지정
드롭다운으로 검색어를 지정하여 검색하는 기능을 구현할 수 있다.
우리는 method 값을 선택하여 검색하는 기능을 만들어주자.
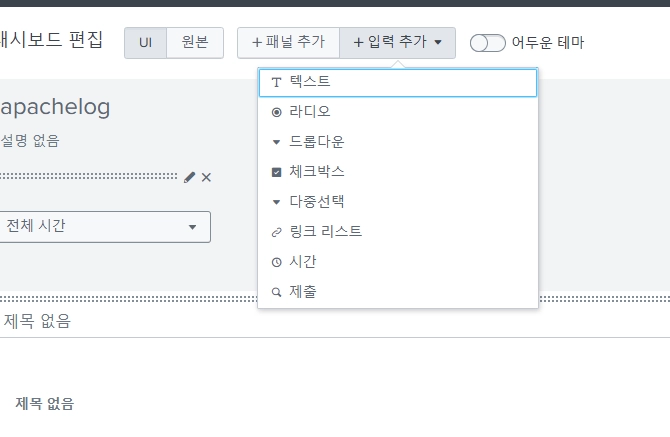
레이블 이름을 지정해주고, 정적 옵션 선택 리스트를 만들어주자.
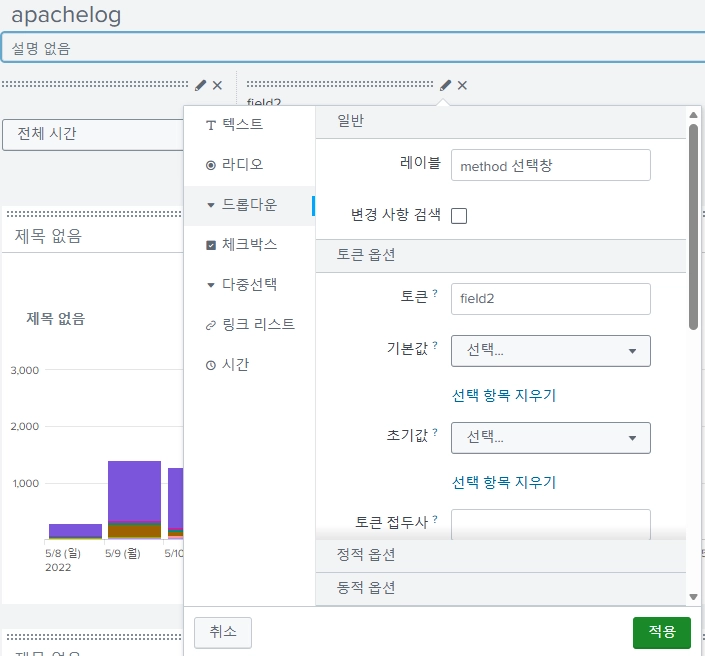

편집 모드에서는 동작하지 않으니 저장을 해준 후 나가서 실행해보자.
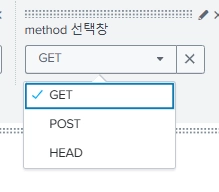
잘 보인다. 그러나 선택한 것에 따라 차트가 맞게 변하지는 않을 것이다. 이걸 적용시켜주려면 원본 코드를 수정해주어야 한다. 이런식으로 생겼다.

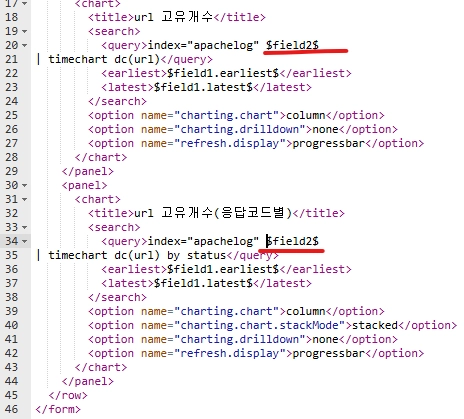
token=field2 부분이 우리가 방금 추가해준 드롭다운 부분이다.
여기에 method=$field2$를 추가해주자.
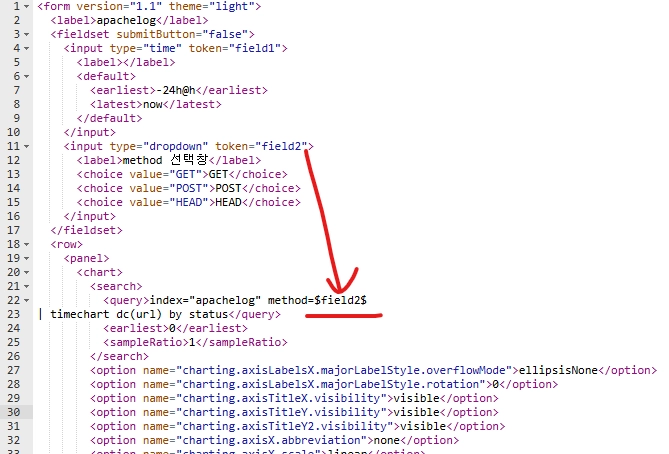
밑에 다른 차트 두 개에도 똑같이 method=$field2$를 추가해주자.

그럼 이제 잘 반영이 되는 것을 확인할 수 있다.
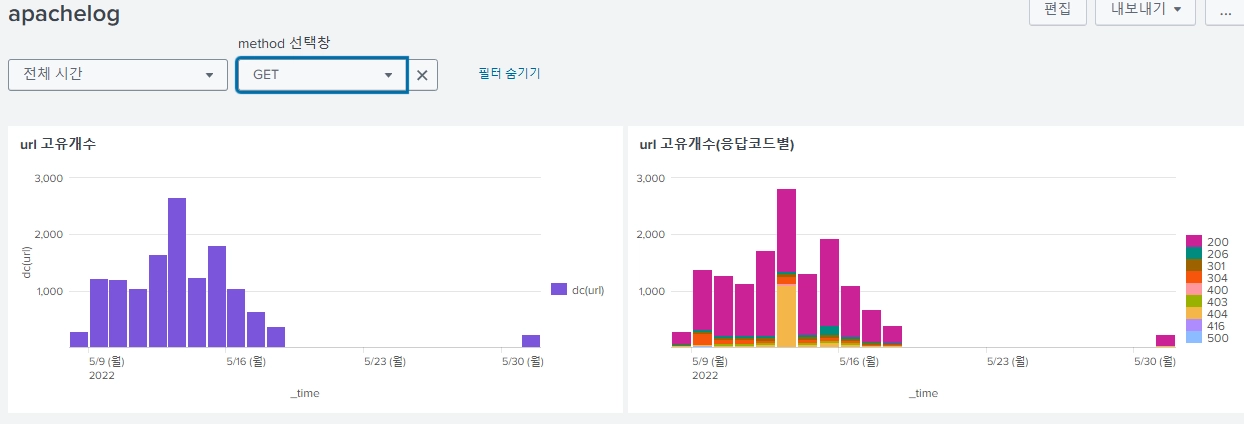

초기 상태 지정
초기 상태가 지정되지 않아서 처음에 들어가면 에러가 난 것처럼 보인다.

디폴트 값을 지정해주는 게 좋아 보인다.
다시 드롭다운 편집창으로 가서 옵션을 하나 더 추가해준다.
ALL *


기본값을 ALL로 설정해준다.
그럼 이제 처음 들어가면 기본값으로 ALL이 들어가서 차트가 잘 나오게 된다.
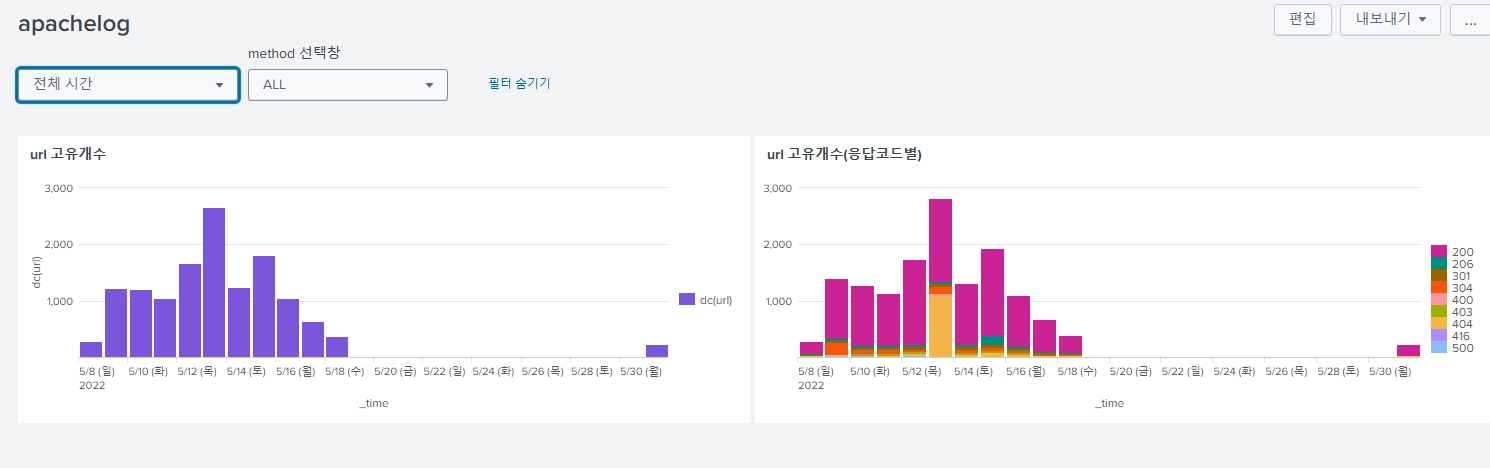
동적 옵션
이번엔 동적으로 method에 있는 값들을 자동으로 불러와서 드롭다운의 값으로 들어가도록 해보자.
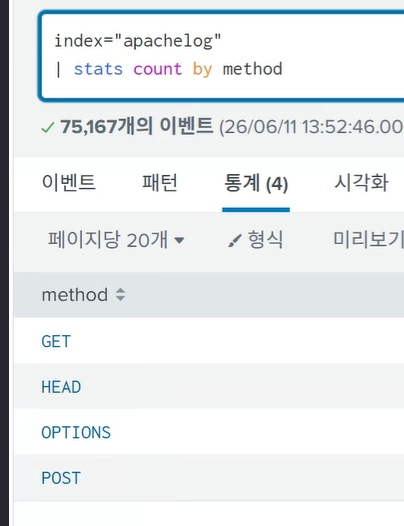
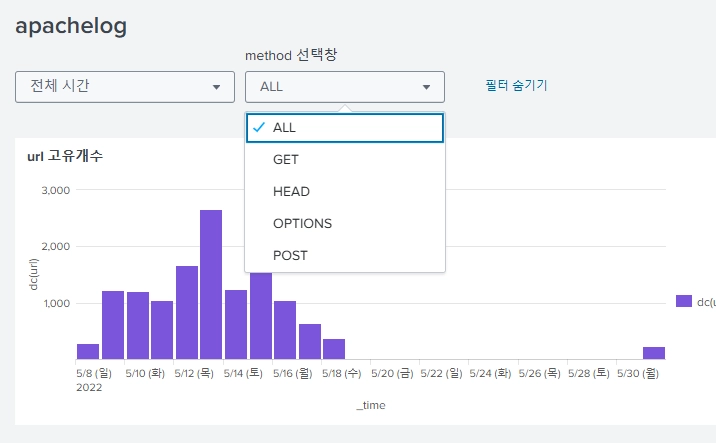
직접 조회해보니 GET, HEAD, OPTIONS, POST 값이 method에 들어가있다. 우리는 이 값들을 모두 드롭다운에 적용시킬 것이다.
드롭다운> 동적옵션으로 가서 입력해주자.
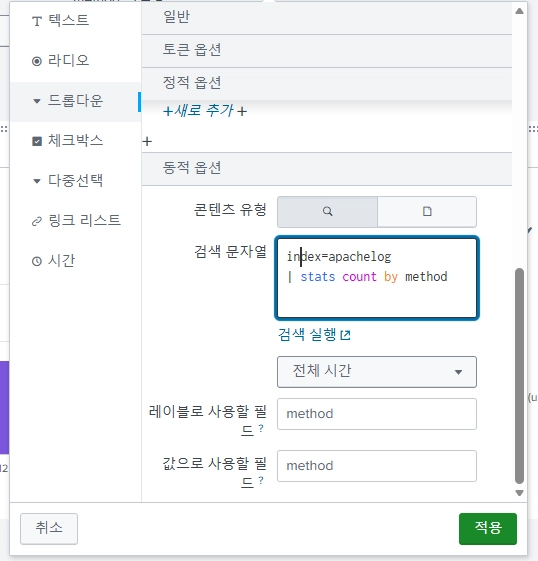
method값만 필요한데 count by를 쓰는 이유?
count를 보고 싶어서 넣은 게 아니라,
| stats by method라는 문법이 없기 때문에
집계 함수 하나가 필요해서 가장 흔한
| stats count by method를 쓰는 것이다.
결과 화면
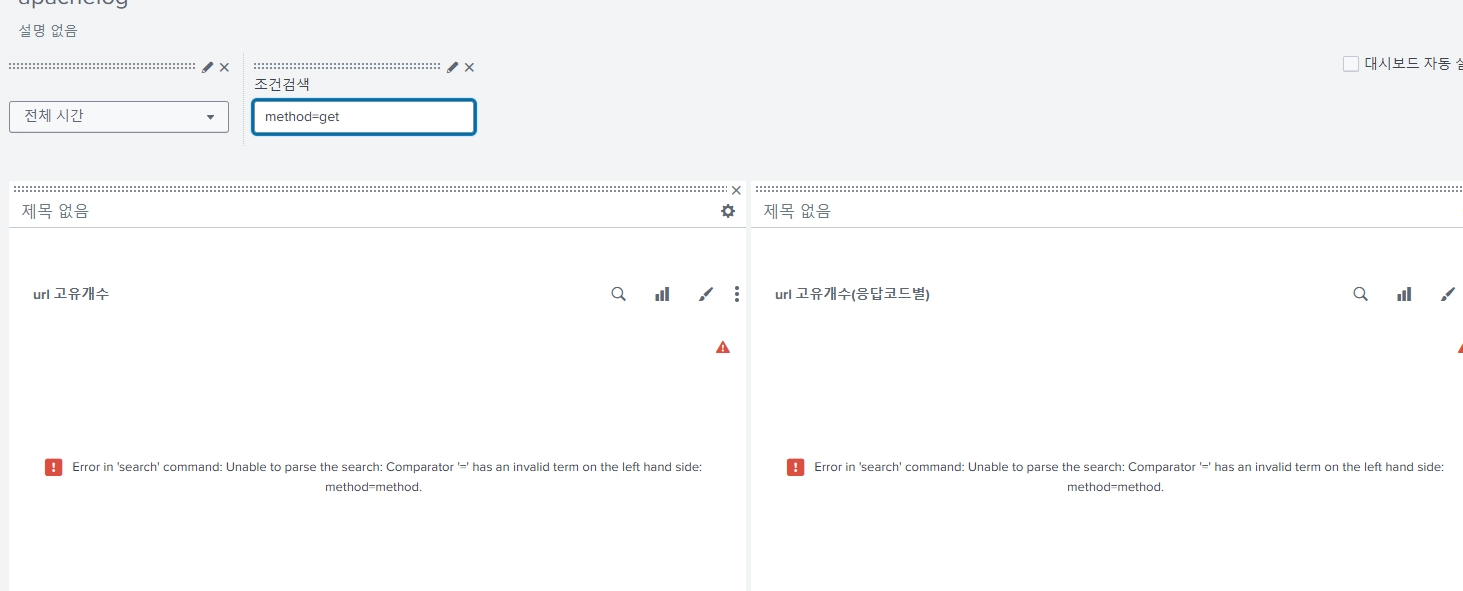
사용자 입력이 바로 검색되도록
이번에는 사용자가 입력한 게 그대로 명령문에 들어갈 것이다. 드롭다운이 아니라 텍스트를 선택해주자.
코드를 다음과 같이 수정해준다. 원래는 method=$field2$였음


진짜 로그 파일로 분석
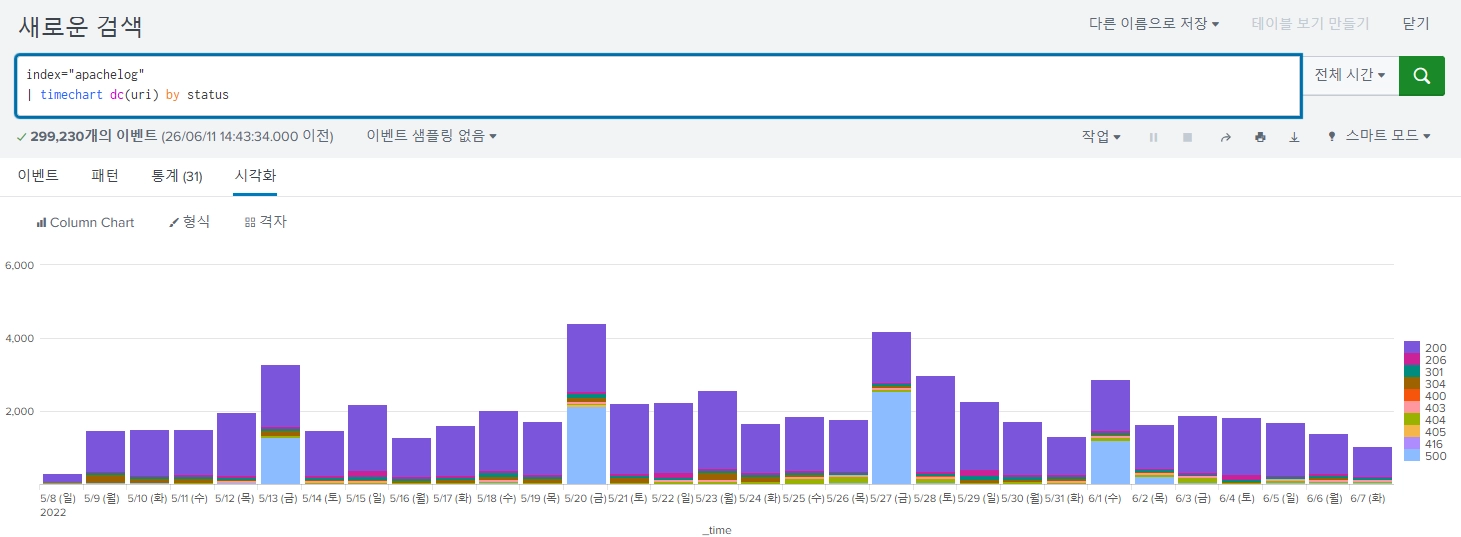
count가 많은 곳을 보니 그때에만 500에러가 많이 일어나있다.
status=500일 때의 uri를 살펴봤다. 그런데 중복된 uri가 없고 다 다른 uri들 뿐이다.
uri를 확인해보면, 웹쉘 업로드 후 cmd 명령 실행하는 시나리오 같다.
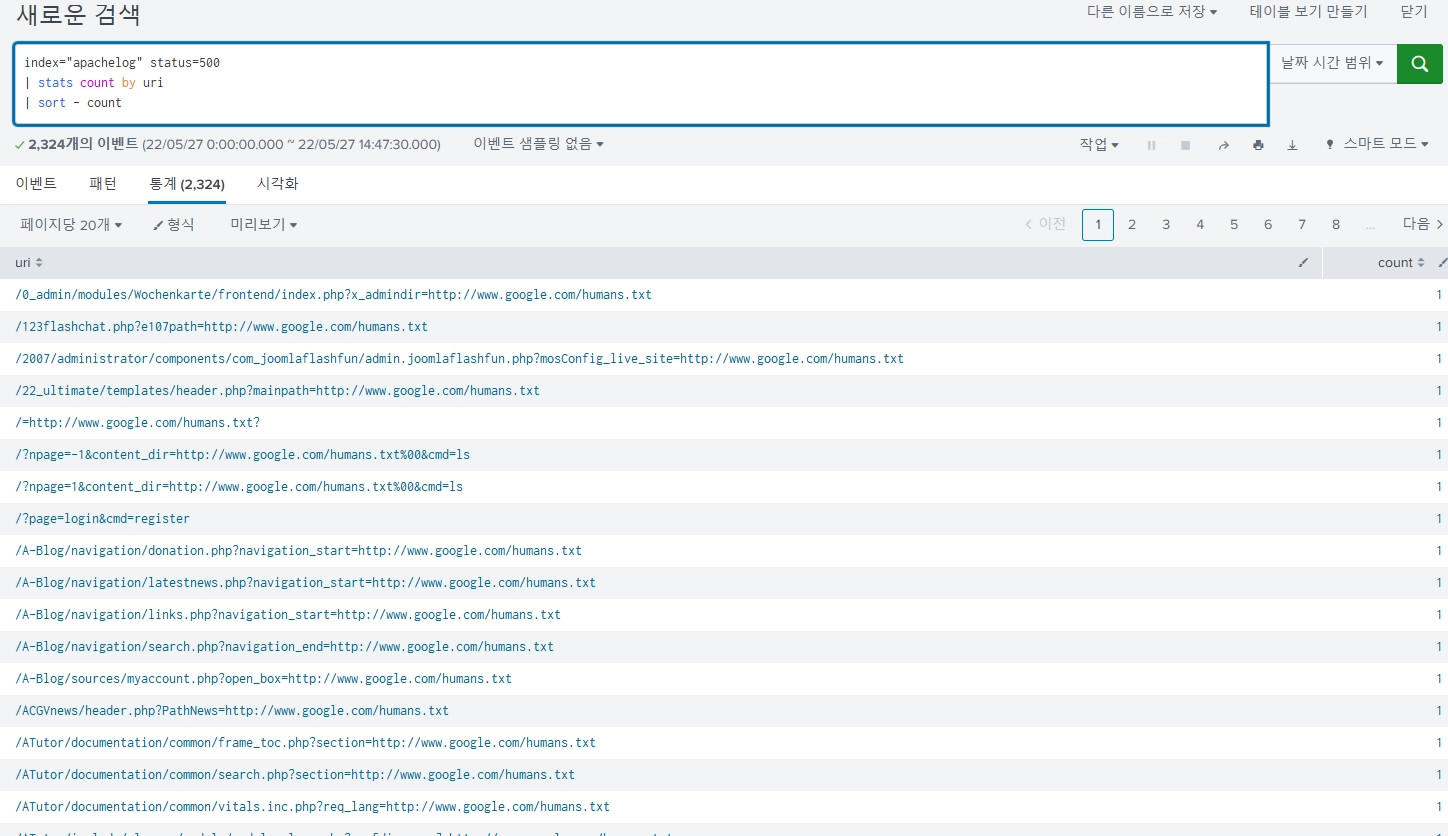
URL
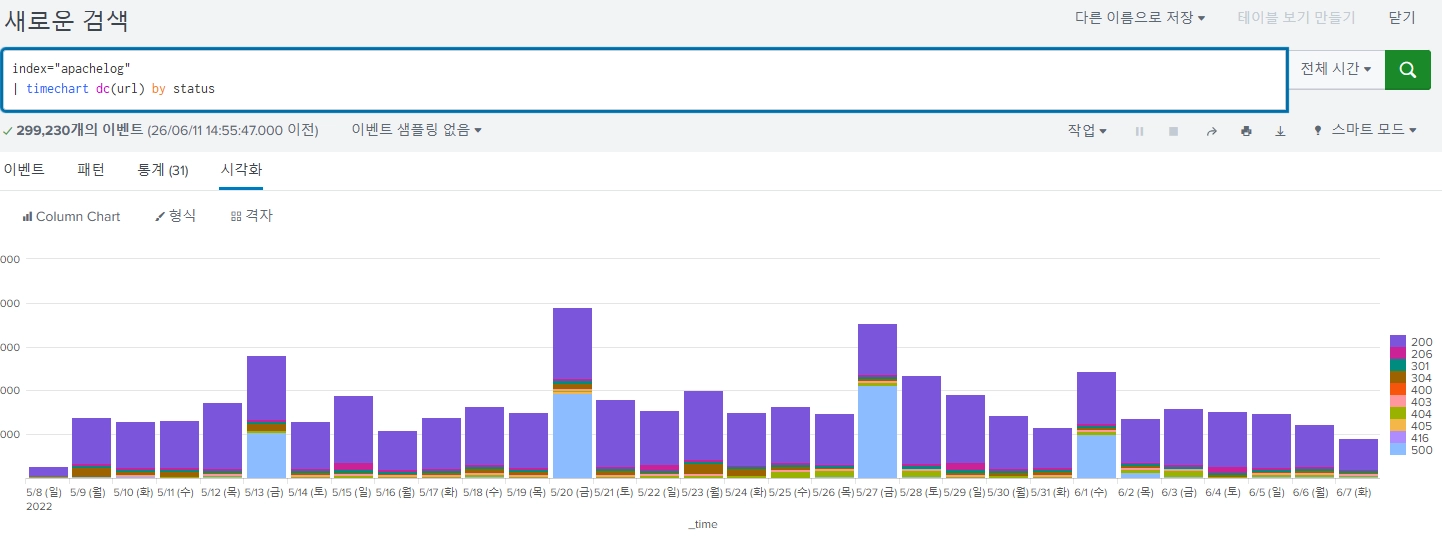
param

url로 봤을 때 보다 param으로 봤을 때 결과가 더 명확하게 잘 나온다.
변수 구간에서 좀 더 뚜렷하게 변화가 발생한다.
변수 고유개수가 증가했을 때 500에러가 많이 발생한다.
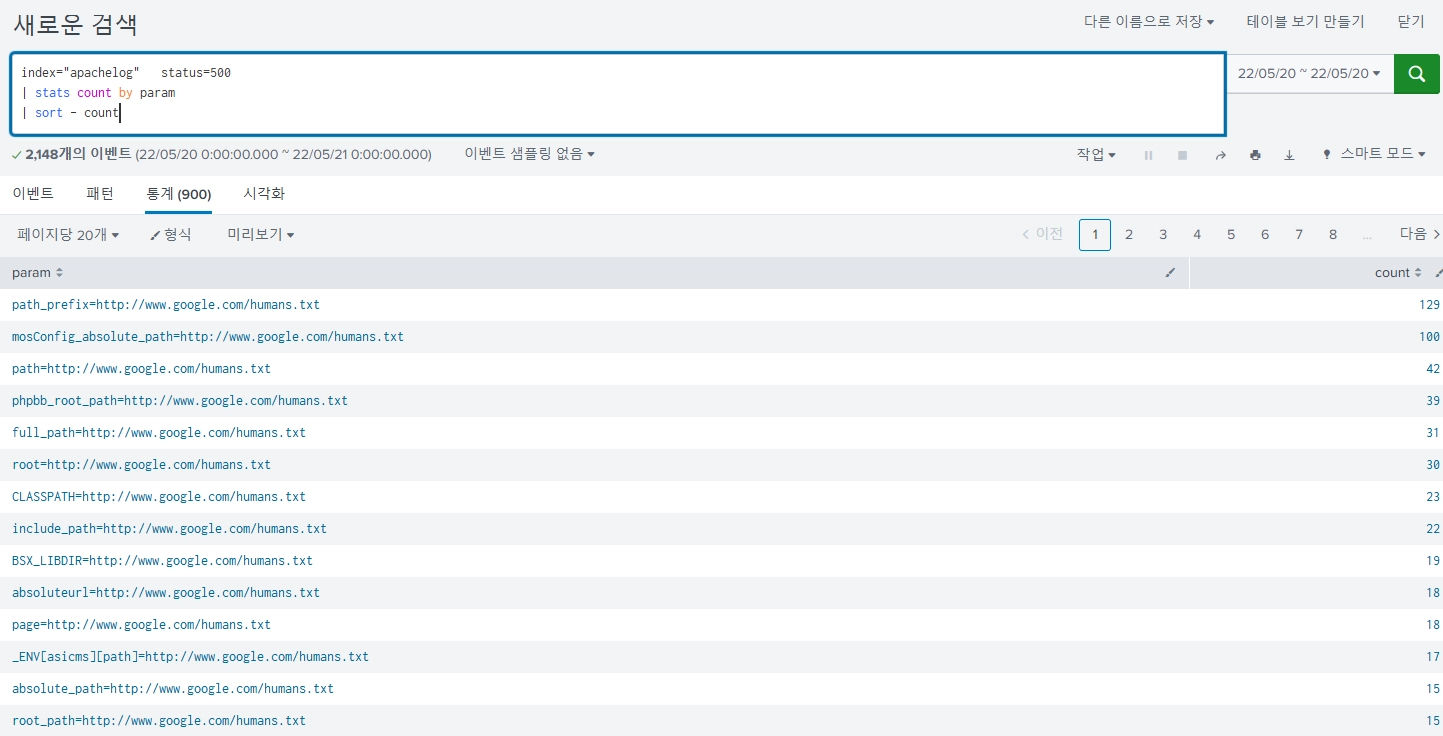
나는 저 하늘색 막대에서 무슨 일이 일어나고 있는지 궁금하다. 저때 어떤 param들이 요청되었을까?
status=500일 때 각 param의 요청 개수를 내림차순으로 불러오는 명령어를 적어주자.
index="apachelog" status=500
| stats count by param
| sort - count
막대 하나 선택하고 명령어 사용하면 내가 궁금해했던 결과를 볼 수 있다.
여러가지 그래프 형태
막대 그래프
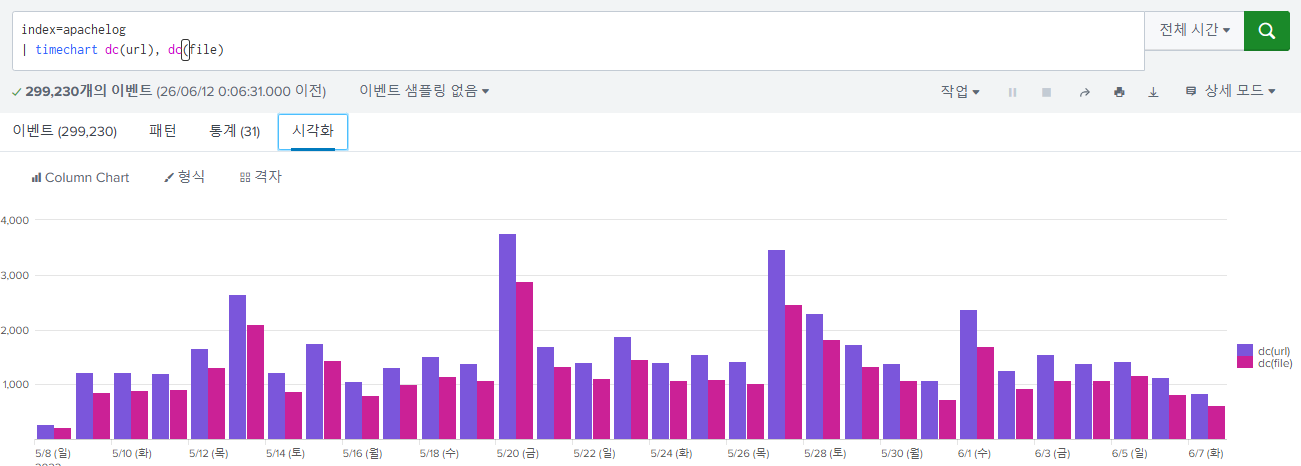
선 그래프

두 개 이상의 변수를 비교할 떄는 선 그래프로 비교하는 게 더 분석하기 쉽다고 한다.
히트 맵 그래프
앱> 앱 업로드에서heat-map-viz_140.tgz 파일을 올려준다.

그리고 method-status 필드를 추가해준다.
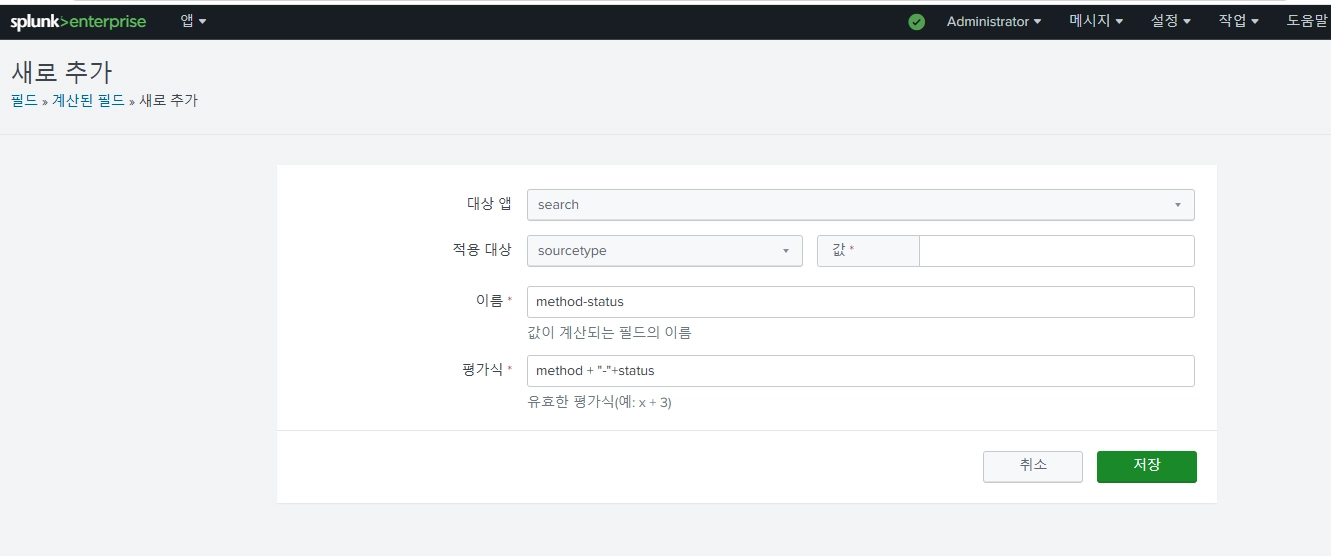
index=apachelog
| eval method-status=method+"-"+status
| timechart count by method-status
이 필드를 고정 값으로 만들어주자. 안 만들어주면 매번 요청때마다
이거 써야 함.
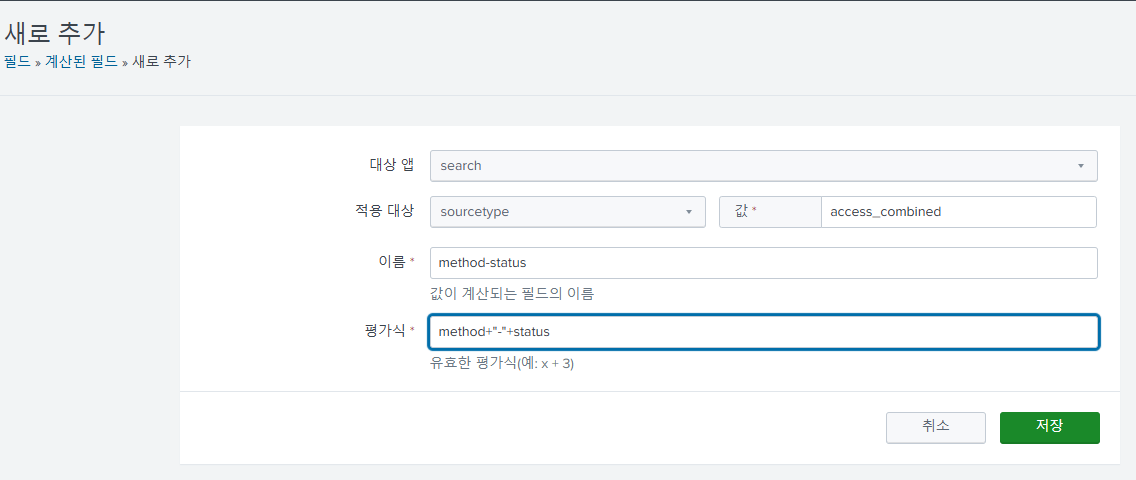
시각화 탭에서 heat map을 눌러준다.
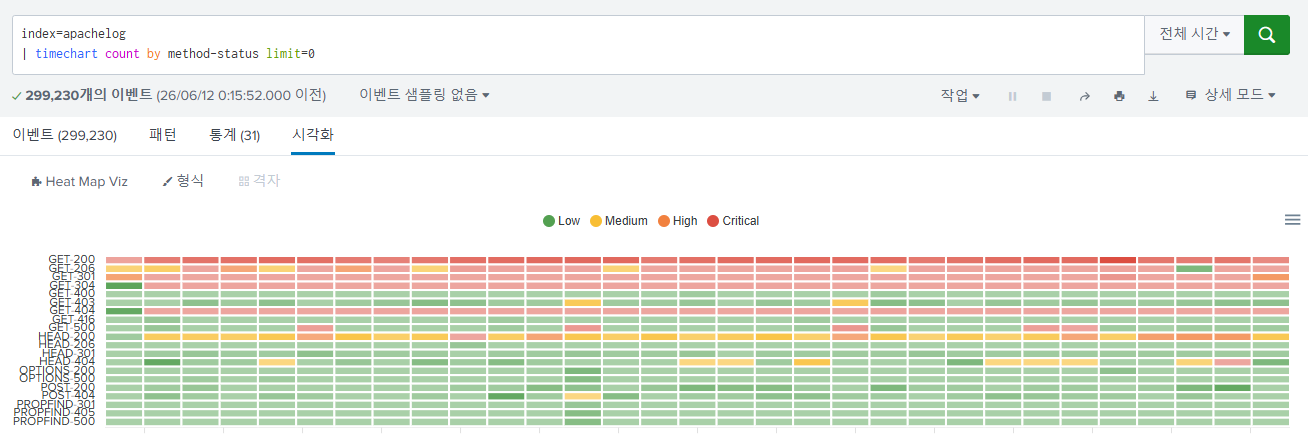
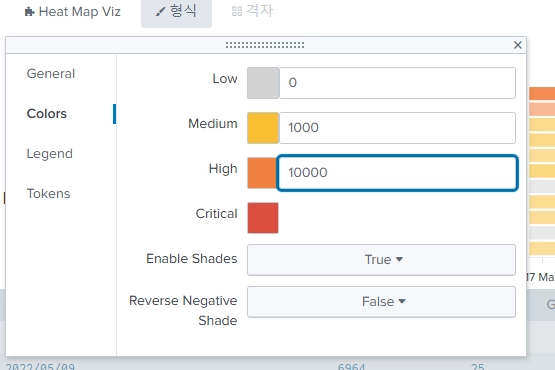
색깔을 바꿀 수도 있다.
0개면 회색, 1000개까지는 노란색, 10000개까지는 주황색, 10000개 넘어가면 빨간색으로 표현한다.
결과 화면
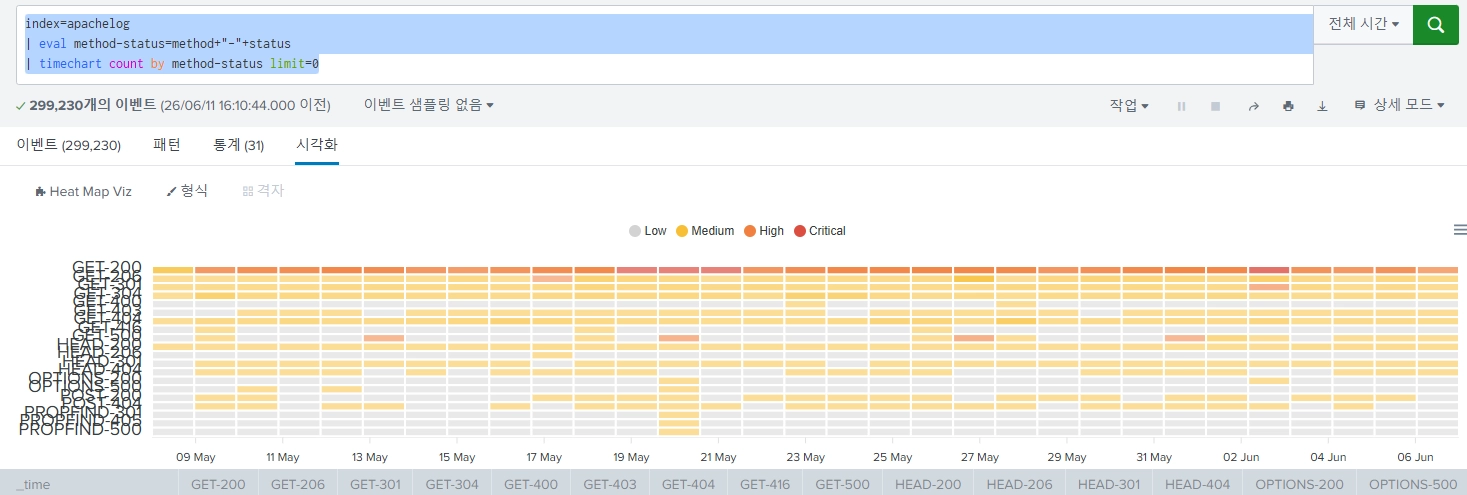
HTTP 300번대 데이터들 제외
300번대 데이터들은 보안 관점에서 별로 중요하지 않은 데이터들이다. 얘네들은 제외하고 추출해보자.
index=apachelog status <300 OR status >399
| timechart count by method-status
limit=0 있는 데이터들은 다 보여줘라. 이거 안 해주면 기본 값으로 limit=10 적용돼버림.
이것도 똑같은 의미이다.
index=apachelog status<300 OR status>399 NOT method IN (get, post, head)
| timechart count by method-status limit=0
일반적이지 않은 method를 사용한 clientip구하기
index=apachelog method IN (options, propfind)
| stats count by clientip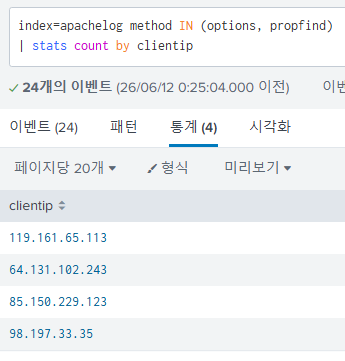
그 ip들이 요청한 url을 내림차순으로 보기
index=apachelog clientip IN (119.161.65.113, 64.131.102.243, 85.150.229.123, 98.197.33.35)
| stats count by url
| sort - count
서브서치(Subsearch)
하나의 검색 결과를 다른 검색의 조건으로 사용하기 위해 먼저 실행되는 내부 검색이다.
Splunk는 서브서치를 먼저 수행한 뒤 그 결과를 메인 검색에 전달하여 최종 검색을 수행한다.
SQL문에서는 서브쿼리를 써서 이 두 개를 이어준다.
select url
from apachelog
where ip in 아래결과
select ip
from apachelog
where method in (options, propfind)
합친 버전
select ip
from apachelog
where ip in (
select ip
from apachelog
where method in (options, propfind)
)
splunk에서…
index="apachelog" method IN (options, propfind)
| fields clientip
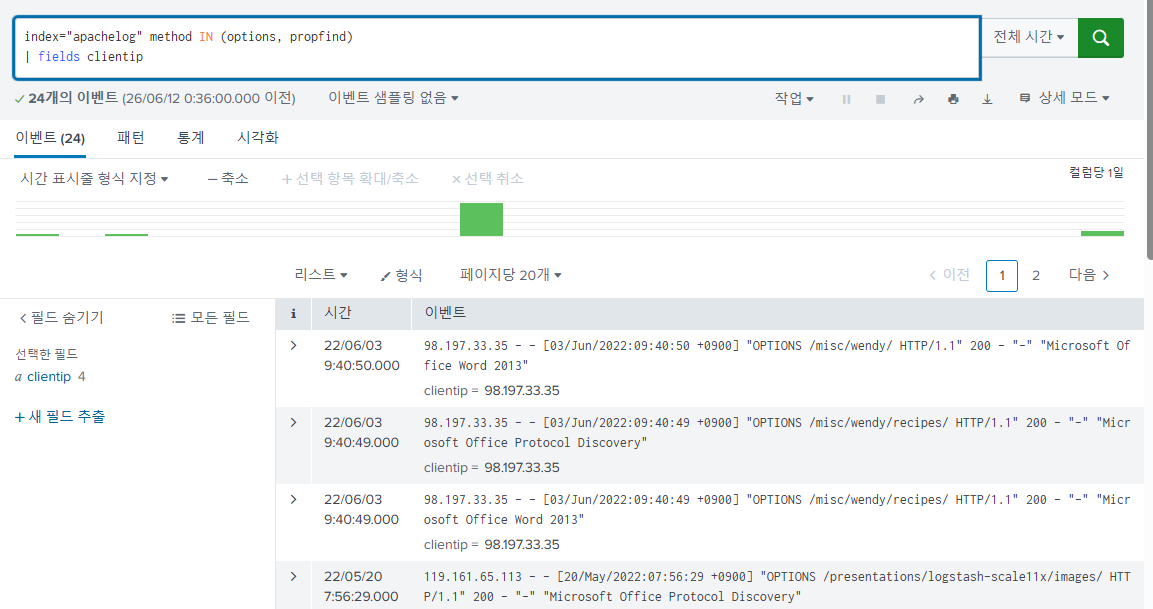
index="apachelog"
[search index="apachelog" method IN (options, propfind)
| fields clientip]
| stats count by url
useragent 필터링 (urldecode)
index="apachelog" useragent=*havij
| eval param2=urldecode(param)
| stats count by param, param2
룩업
CSV 파일을 기준으로 로그 데이터에 추가 정보를 붙이는 기능
공통 필드 하나를 기준으로 연결된다. 여기서는 status 필드를 기준으로 연결이 된다.
룩업 » 룩업 테이블 파일 » 새로 추가

status.csv 파일은 이렇게 생겼다.
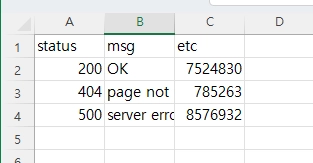
index=apachelog
| lookup status status
excel 파일에 있던 status, msg, etc 필드가 잘 나오는 것을 확인할 수 있다.

lookup <룩업테이블명> <로그필드> OUTPUT <가져올필드>
index=apachelog
| lookup status status output msg
| stats count by status, msg.csv파일에 있는 필드를 쓰려면 output으로 지정해줘야 한다.
Q. status는 output 지정 안해줘도 됨?
A. ㅇㅇ 왜냐하면 status는 원래 Apache 로그에 이미 존재하는 필드이기 때문이다.
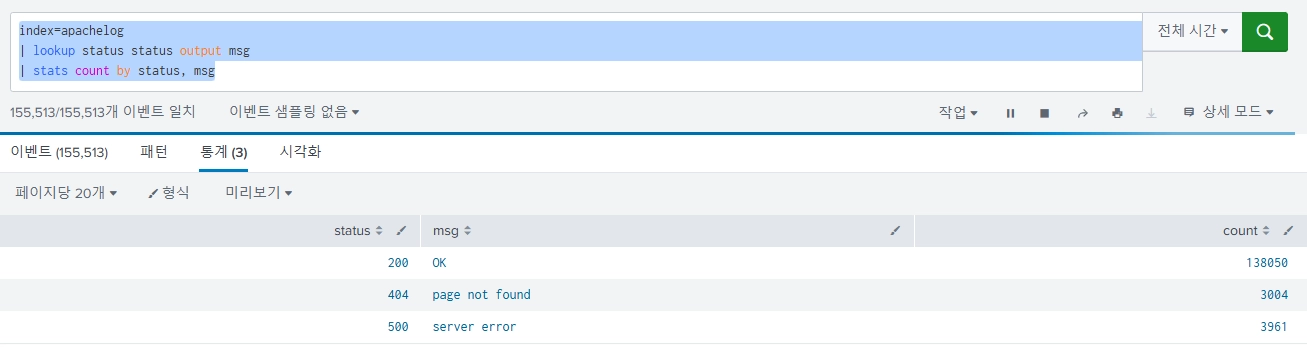
output msg: 룩업 파일의 msg 컬럼을 가져와라
'보안 > SK 쉴더스 루키즈' 카테고리의 다른 글
| [SK 쉴더스 루키즈] Splunk Universal Forwarder를 이용한 로그 수집 및 전송 (0) | 2026.06.11 |
|---|---|
| [SK 쉴더스 루키즈] 보안관제 - Splunk 사용법 & vim에서 데이터 전처리 & Excel 피벗 테이블 (0) | 2026.06.11 |
| [SK 쉴더스 루키즈] AutoIt 스크립트 분석(Citadel 변종 증명) (0) | 2026.06.06 |
| [SK 쉴더스 루키즈] Malware Traffic Analysis - INFECTION TRAFFIC FROM ITALIAN DHL-THEMED MALSPAM 문제 풀이 (0) | 2026.06.06 |
| [Malware Traffic Analysis] Email Roulette 문제 풀이 (0) | 2026.06.06 |



